OCR & Data Processing
Automated OCR and Data Processing
This showcase demonstrates how Automated OCR and Data Processing can transform unstructured chaos into structured value. We tackle documents of any complexity – extracting text, retrieving embedded tables, and analyzing content with AI precision.
The architecture is flexible, orchestrated by n8n for seamless workflow logic. Depending on data sensitivity, we implement two powerful approaches:
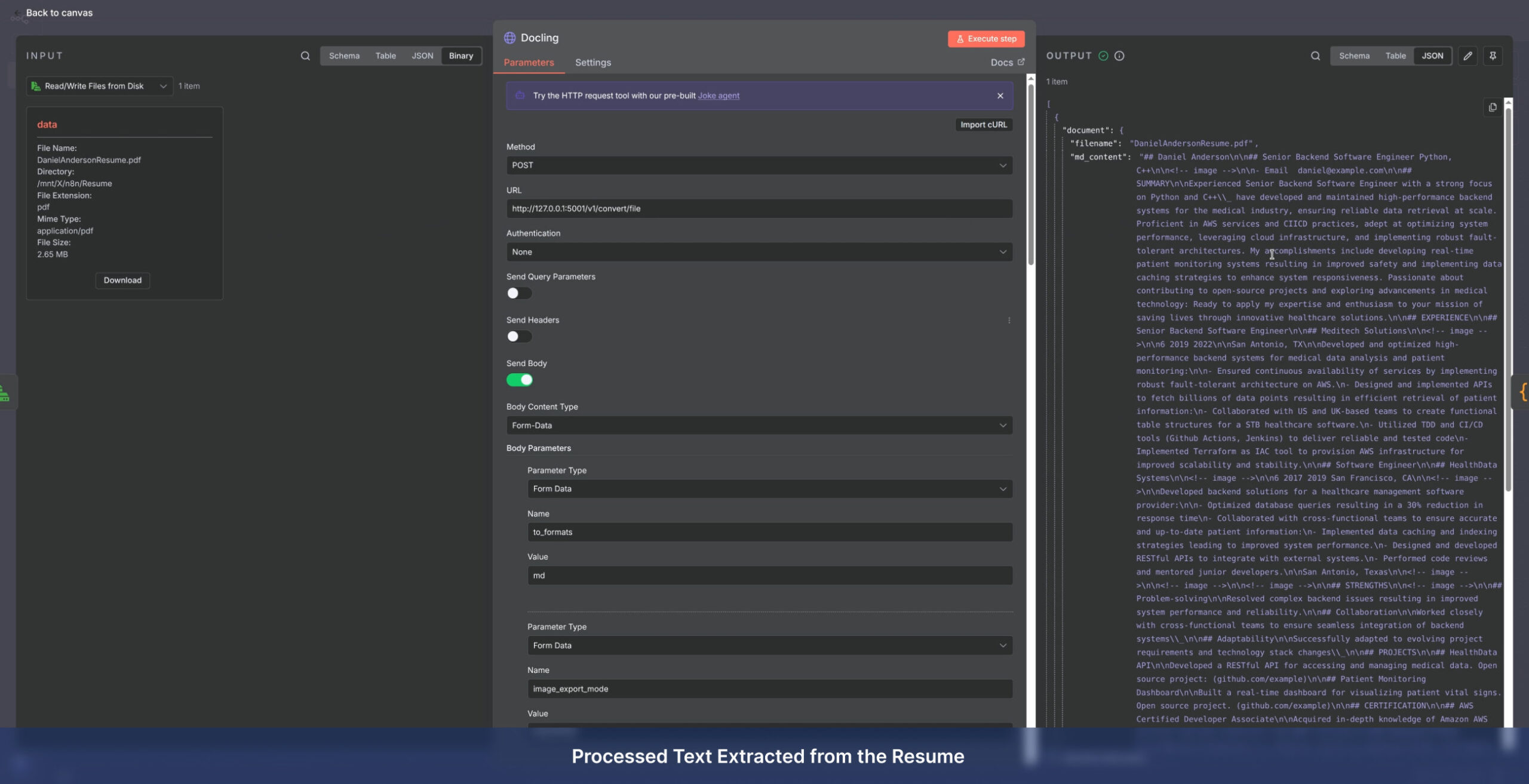
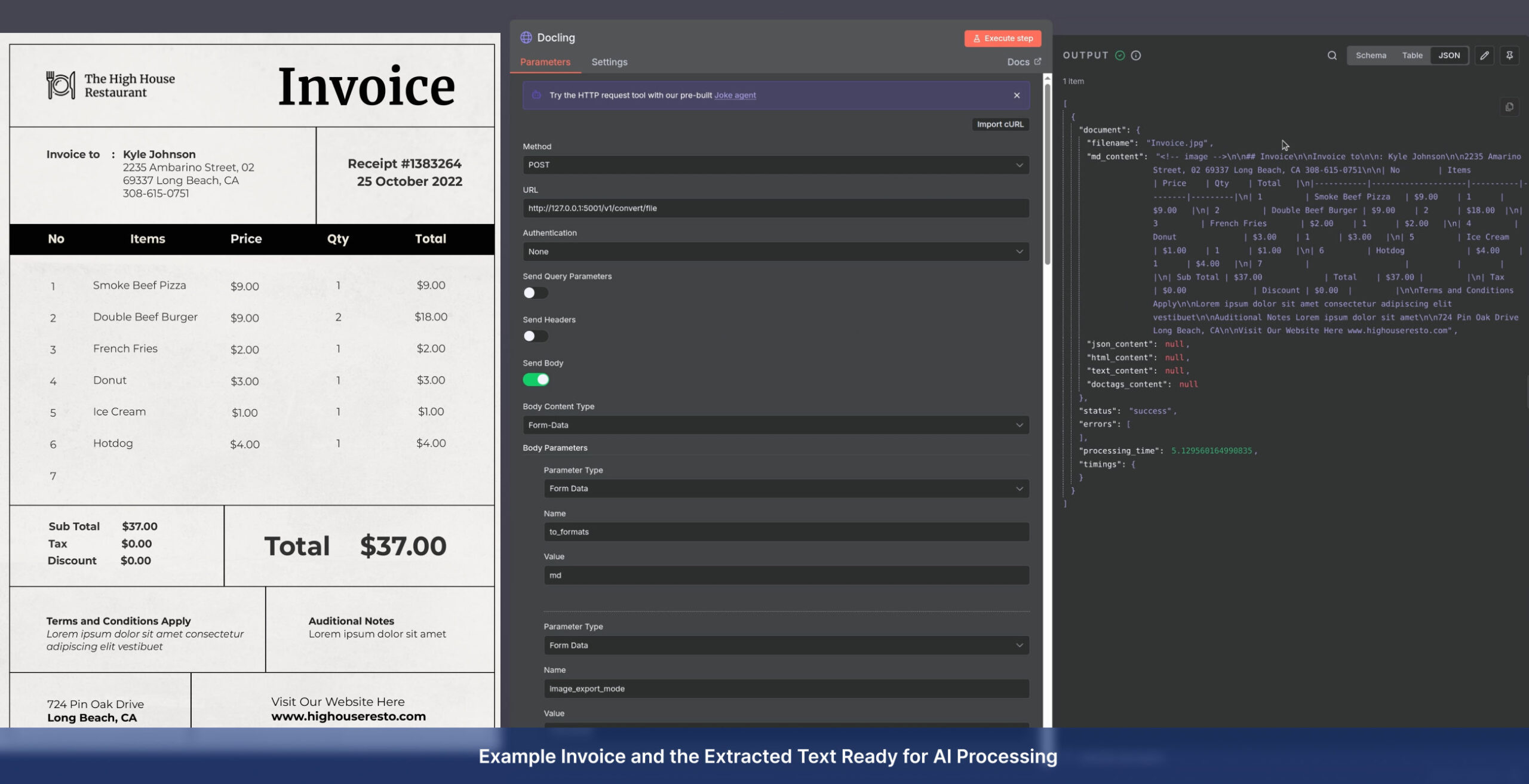
Privacy-First Local Processing: Utilizing IBM Docling for fully offline, secure extraction directly on your server.
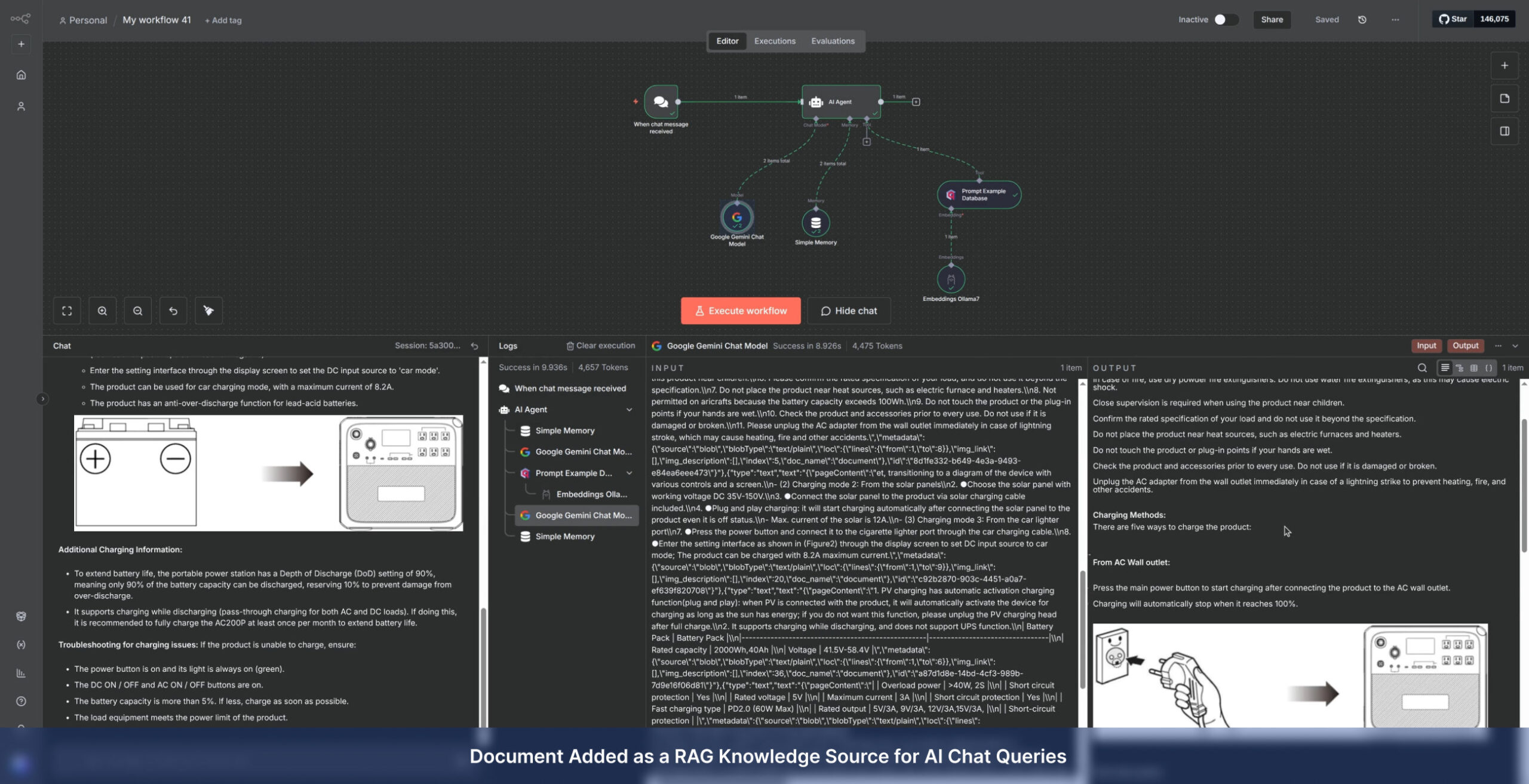
Advanced Parsing: Leveraging LlamaIndex for complex, cloud-based retrieval and semantic understanding.
System Capabilities
- Hybrid Pipelines: Support for both cloud-based and fully offline, local processing
- Bulk Operations: Processing hundreds or thousands of files in a single workflow
- Universal Ingestion: Automated OCR for scanned PDFs, images, and multi-page documents
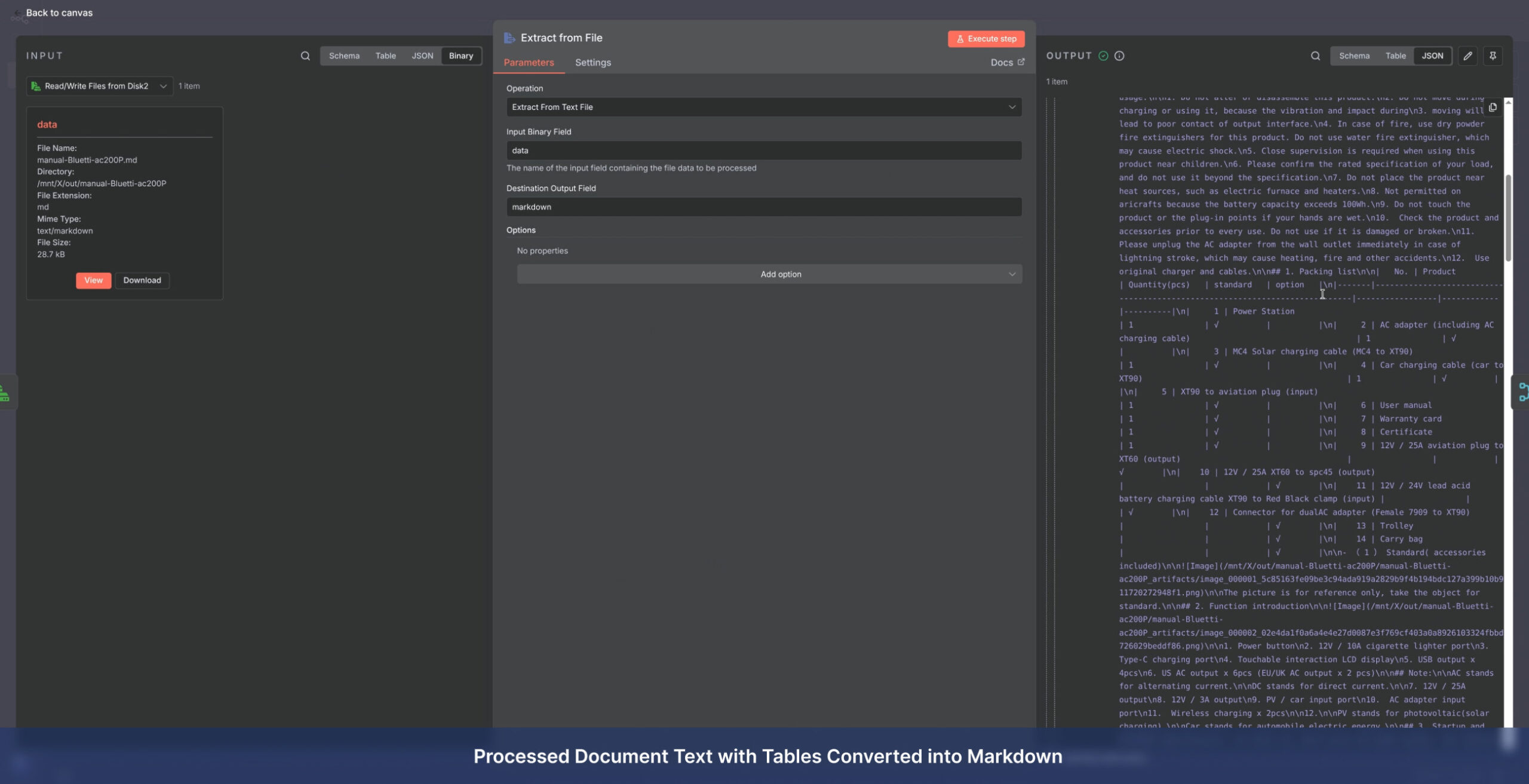
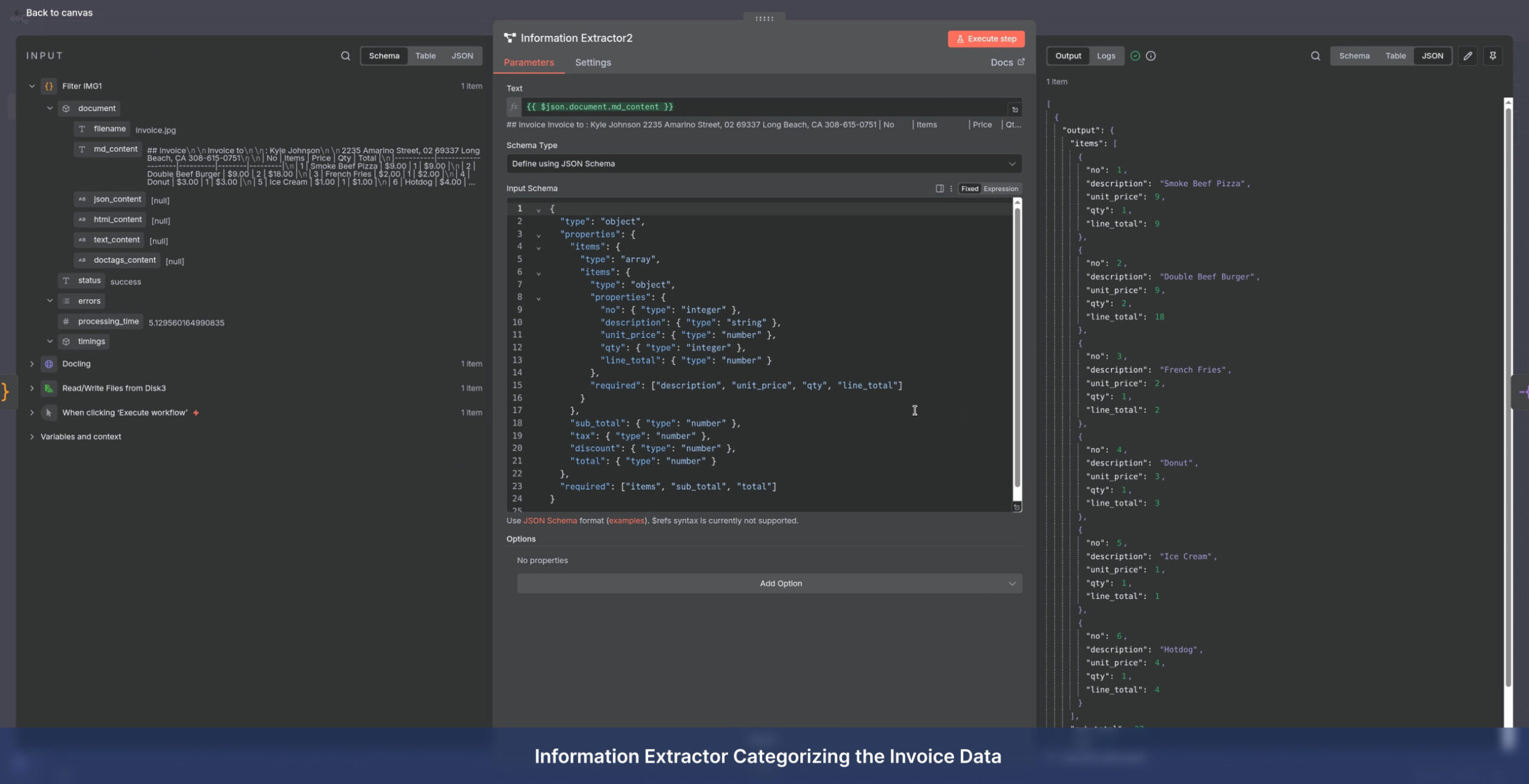
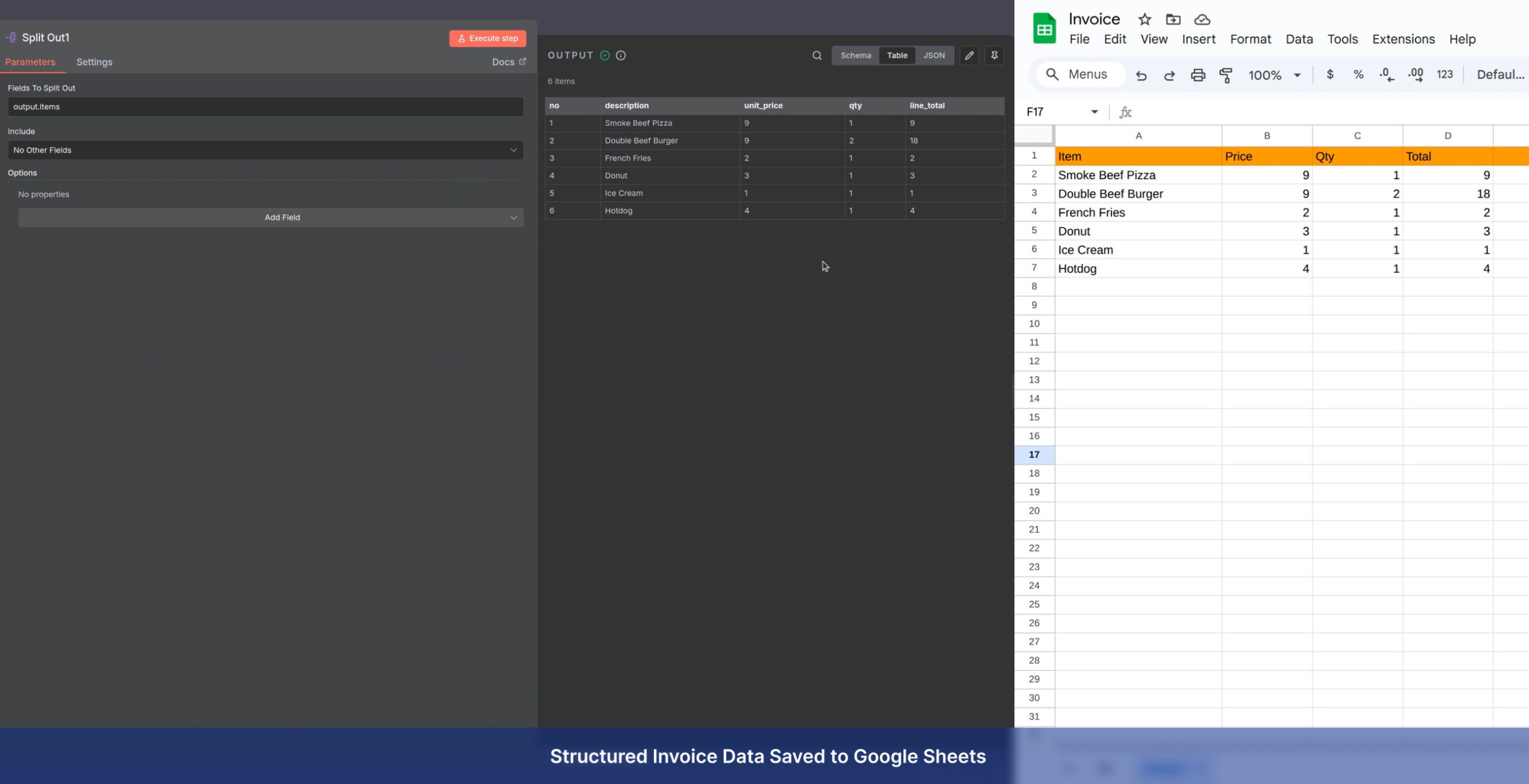
- Deep Extraction: Accurate retrieval of text, key fields, complex tables, and embedded images
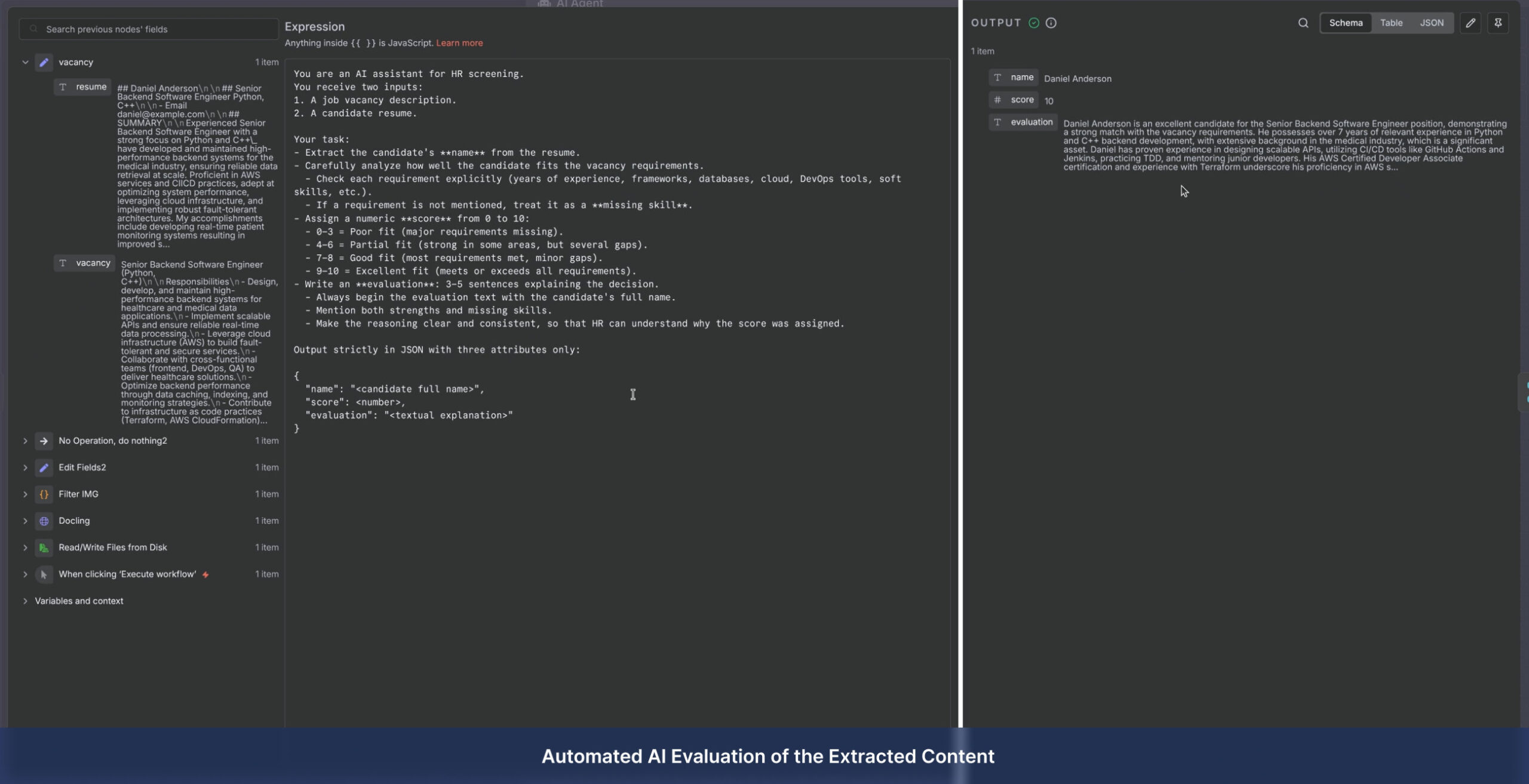
- AI Structuring: Converting raw data into structured JSON for invoices, forms, and corporate documents
- Validation Logic: Intelligent AI analysis for relevance scoring prior to database insertion
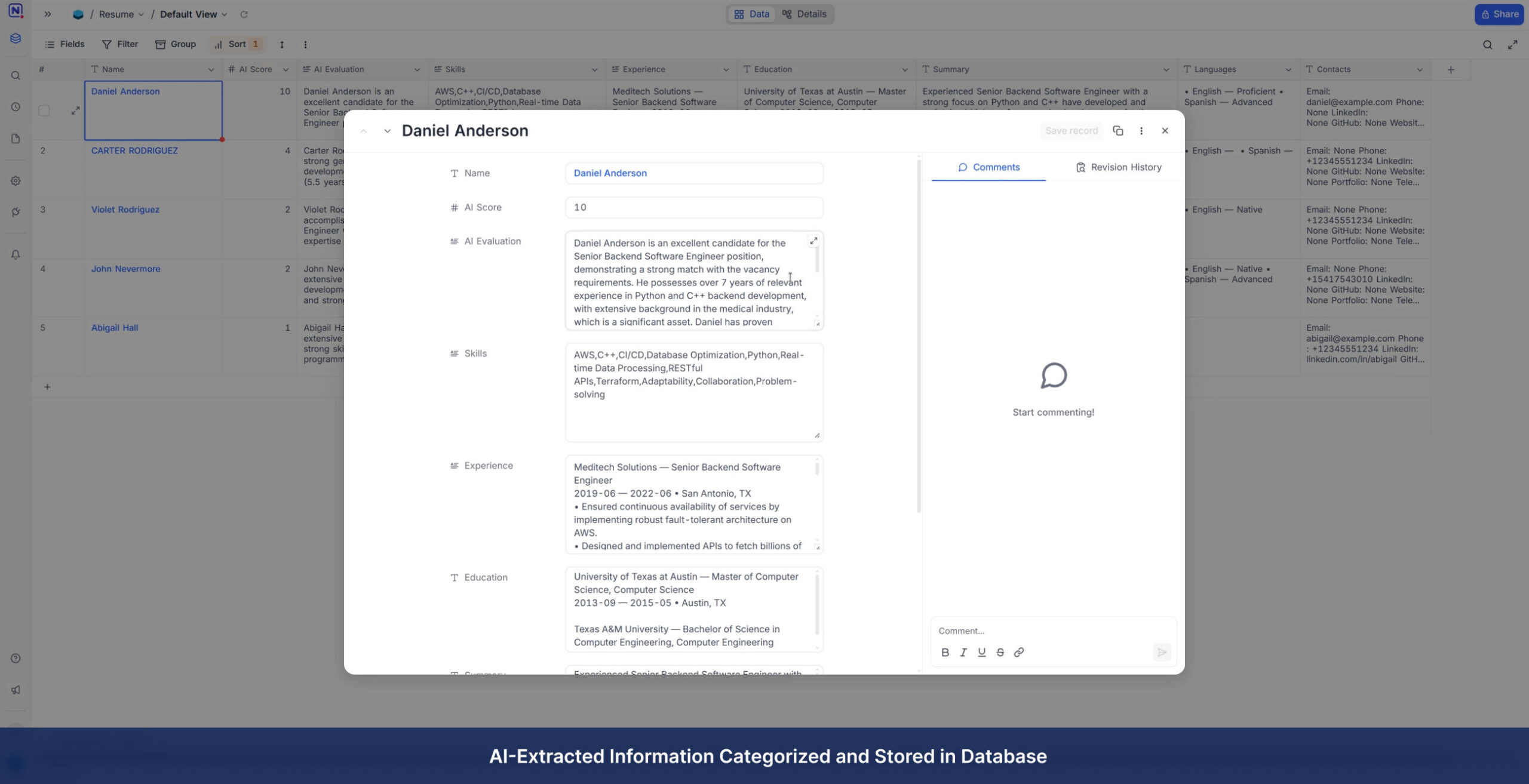
- Seamless Export: Direct sync to SQL databases, spreadsheets, and CRM systems


Video
Automate Your Document Workflow
Do you need to process thousands of invoices or contracts securely? This showcase represents just a fraction of our capabilities.
Visit our AI Visual Search and Recognition Service page (or OCR Service page if you have a separate one) to learn how we can build a custom Automated OCR and Data Processing pipeline for your business.