OCR and Document Processing
OCR and Document Processing Solutions
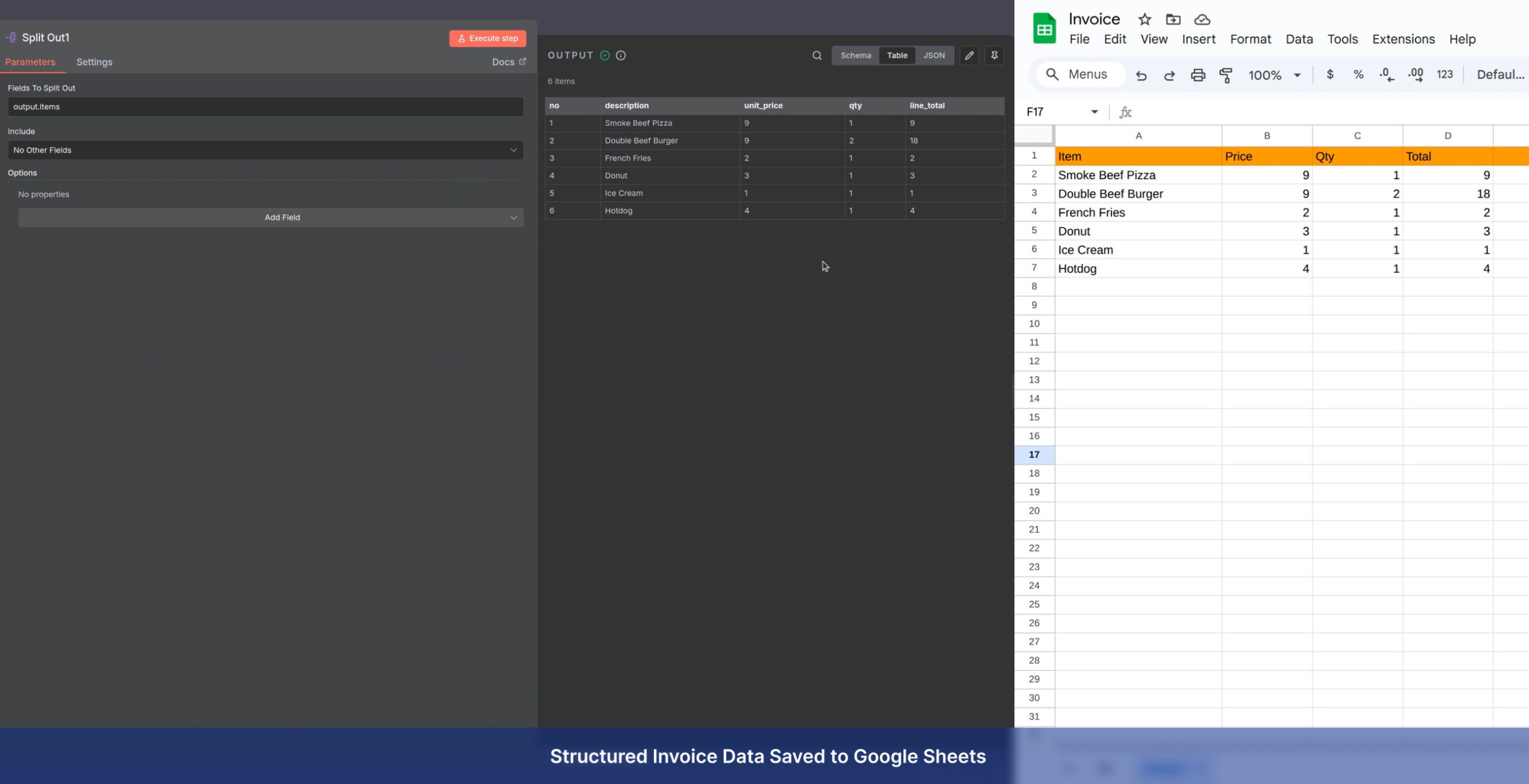
Manual data entry is the bottleneck of modern business. Enceladus delivers professional OCR and Document Processing services that transform your static archives, PDFs, and scanned images into intelligent, editable, and searchable databases.
Instead of manually typing out information from invoices, contracts, or forms, our systems automatically extract and structure the data you need, integrating it directly into your internal workflows.

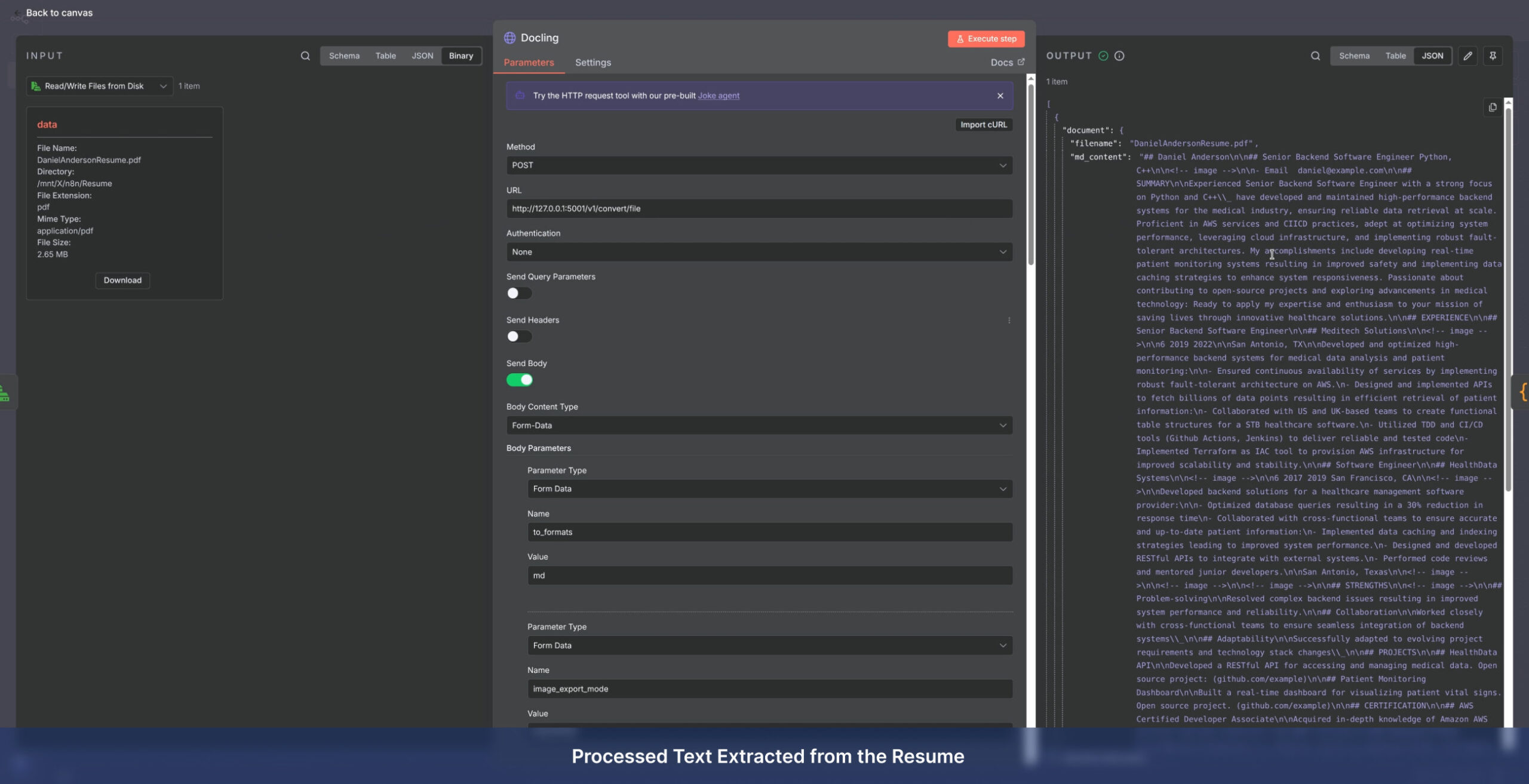
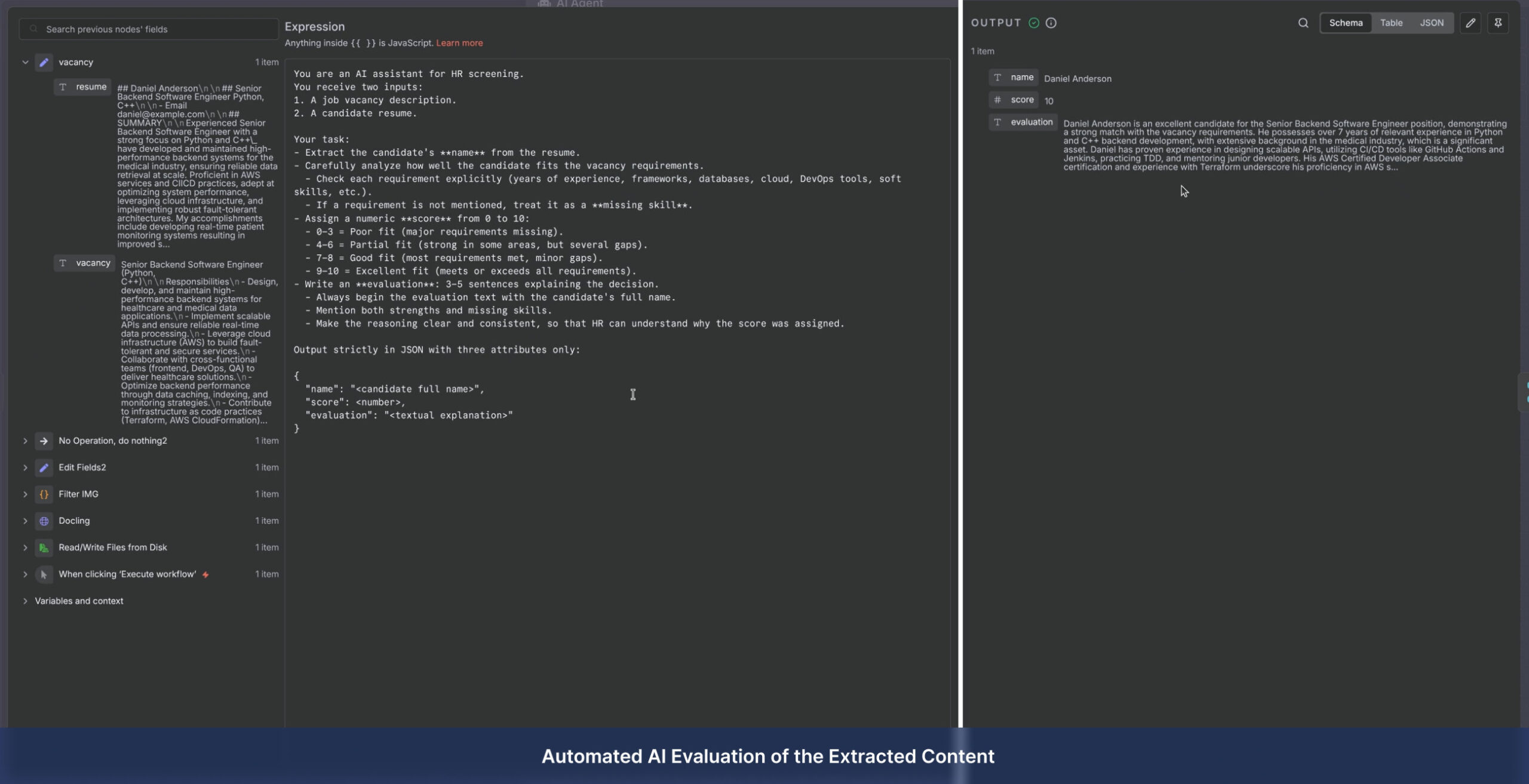
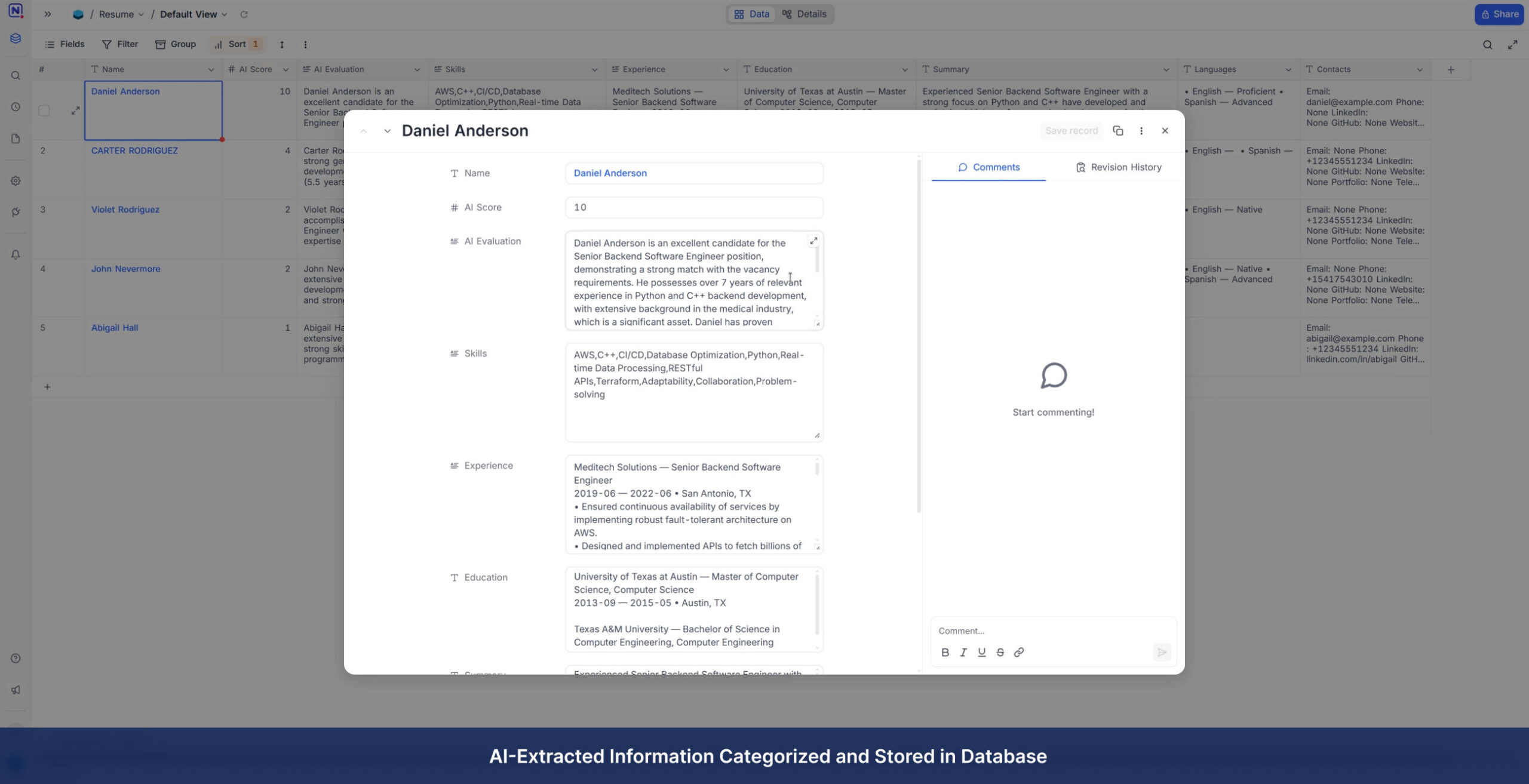

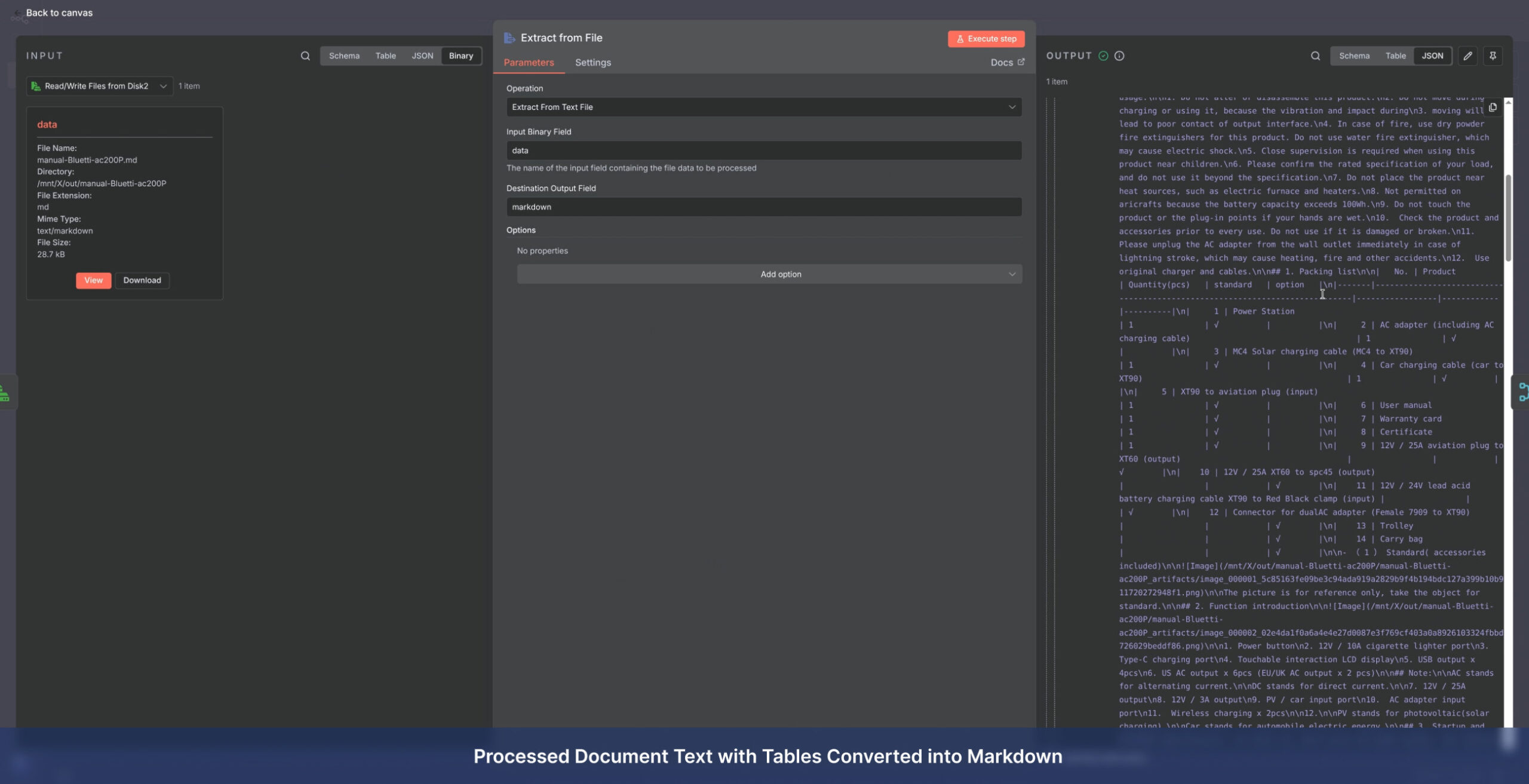
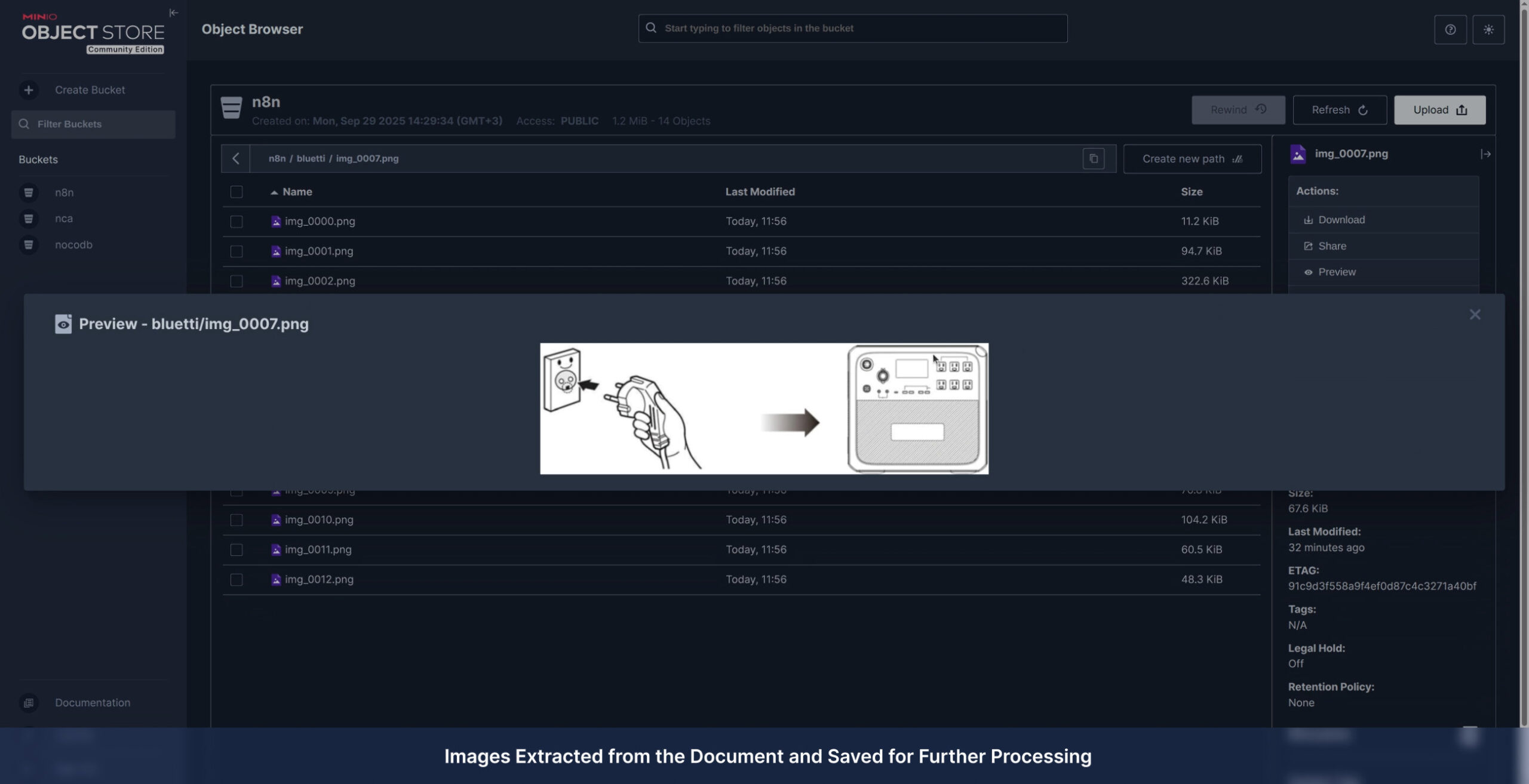
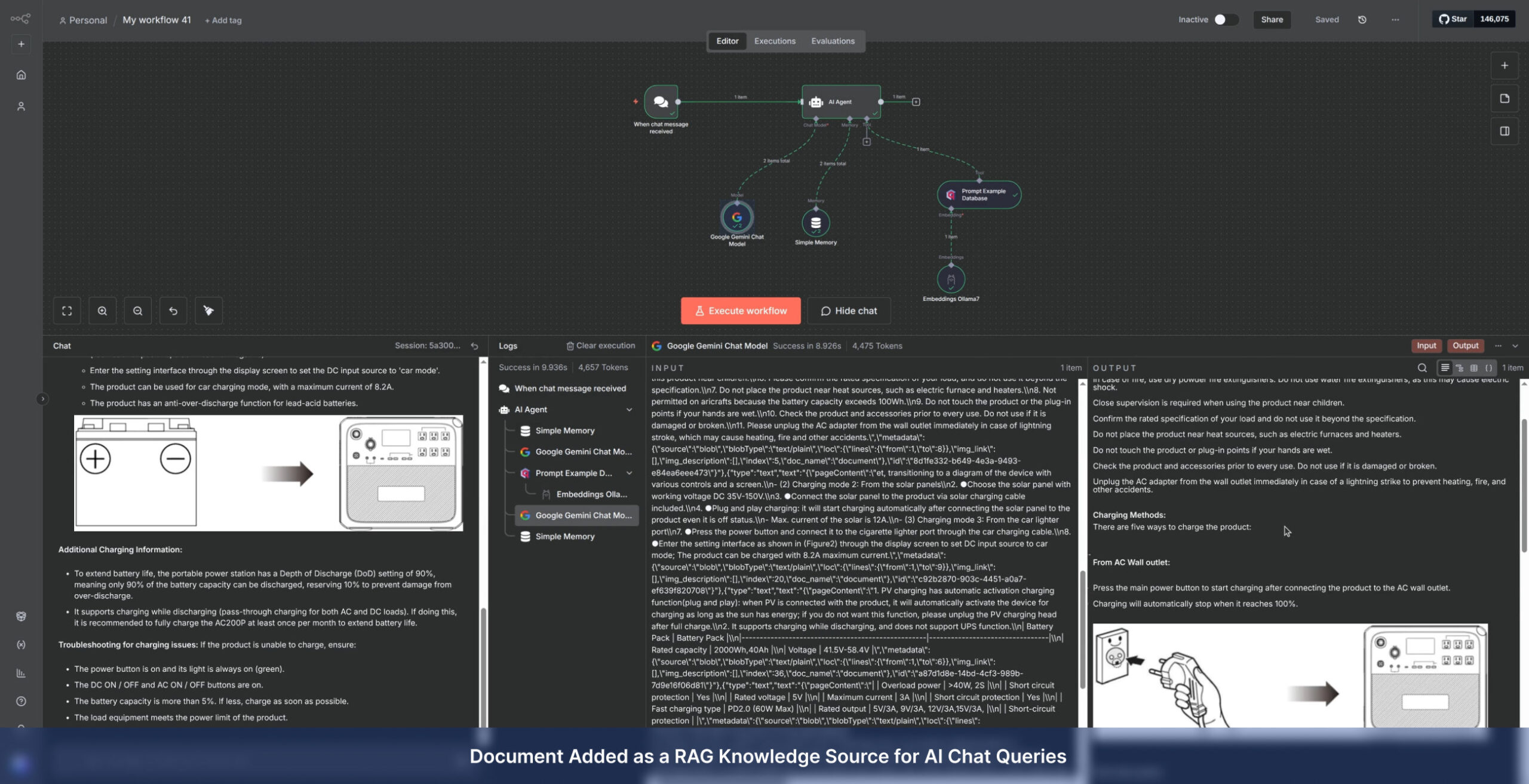
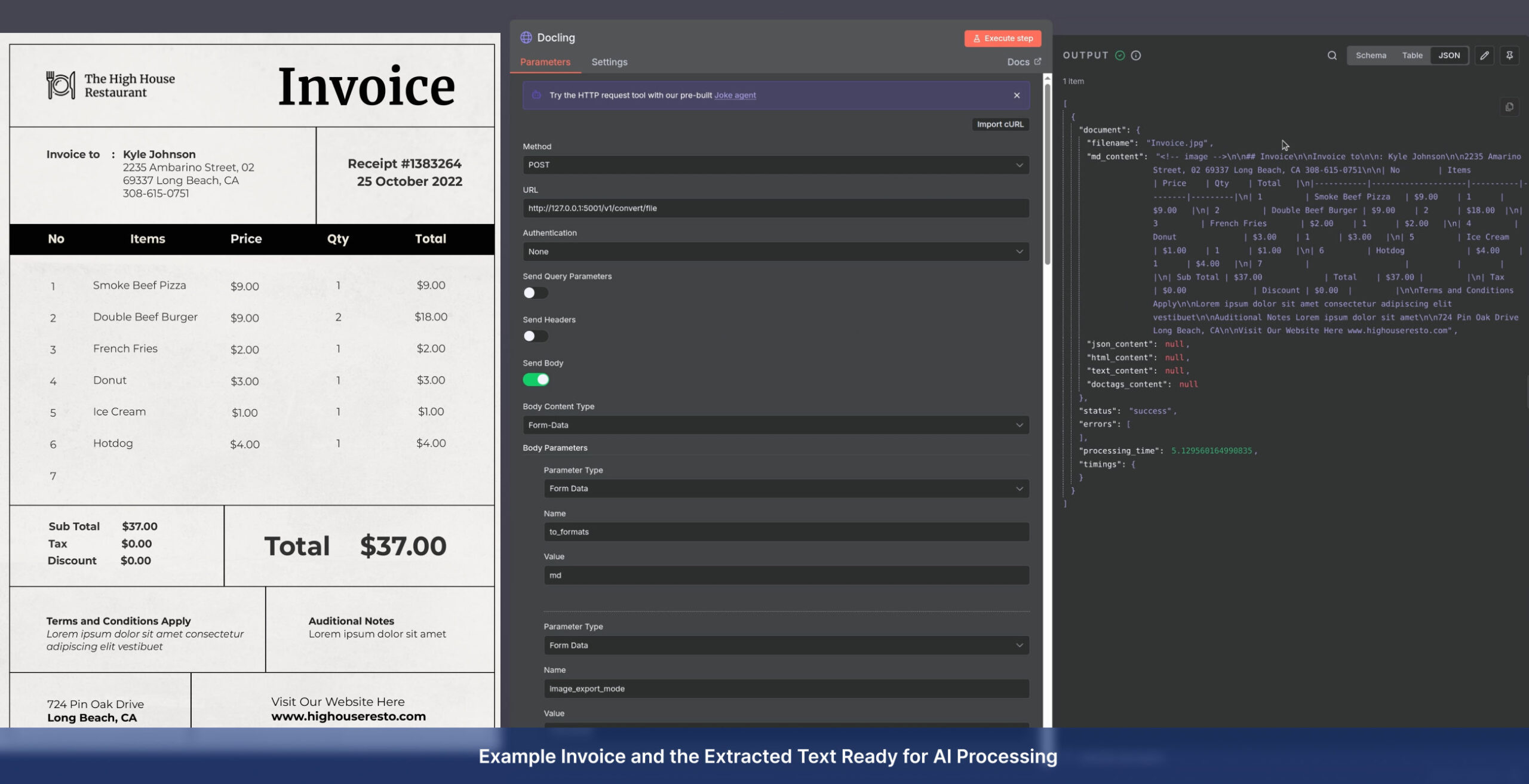
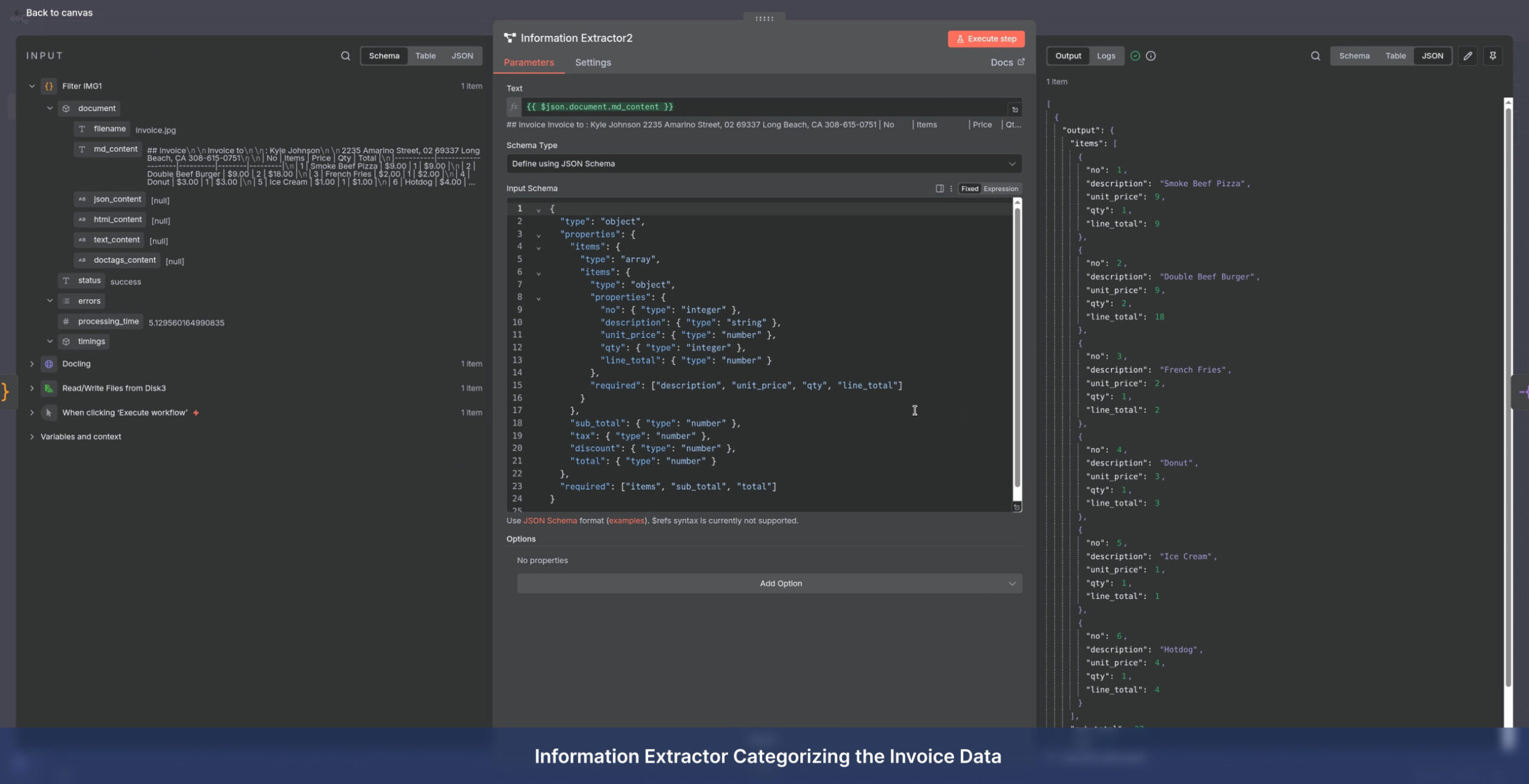
Service Delivery Models
We offer two distinct engagement models tailored to your infrastructure preferences and document volume:
1. Automated Workflow Development (Infrastructure)
We build and deploy a custom processing pipeline directly on your infrastructure.
- How it works: We orchestrate the system (powered by n8n) on your own server or VPS.
- Best for: Businesses that require total control, strict data privacy, and continuous internal processing of daily documents.
- Hardware: Requires a capable VPS/Server for local processing, OR a lightweight setup if using cloud APIs.
2. Managed Data Extraction Service (Batch Processing)
You don’t need servers, software, or technical teams. You simply provide the files, and we return the clean, structured data.
- How it works: You upload files (via FTP, Cloud Storage, or API), and our infrastructure handles the heavy lifting.
- Best for: One-time migration of archives, parsing thousands of PDFs without IT overhead, or clients who don’t want to maintain their own servers.
Technology Stack & Engine Flexibility
Our pipelines are orchestrated by n8n, giving us the flexibility to swap the underlying recognition engine based on your hardware resources and privacy requirements.
Primary Engine: Secure Local Processing (Privacy-First)
By default, we utilize IBM Docling running locally on the server.
Benefits: Data never leaves the perimeter (GDPR/NDPR compliant) and there are no per-page API fees.
Requirements: Requires allocated server resources (CPU/RAM) to process documents efficiently.
Alternative Engines: Cloud API Integration
If you prefer a lightweight setup without maintaining powerful servers, we can connect the pipeline to external cloud engines like Mistral OCR or LlamaIndex.
Benefits: Minimal server load (runs on basic hardware) and high scalability.
Trade-off: Data is processed via secure external APIs rather than locally.
What We Process
Our advanced recognition models are tuned for complex business layouts, going far beyond simple text extraction:
Financial Records: Invoices, receipts, bank statements, and tax forms (extracting dates, totals, line items, and vendor details).
Legal & HR: Contracts, NDAs, resumes, and employee records.
Logistics: Bills of lading, delivery notes, and customs declarations.
Technical: Engineering diagrams, blueprints, and equipment manuals (including table extraction).
Identity: ID cards, passports, and driver licenses (with strict privacy masking).
Output Formats & Integrations
We don’t just extract text; we convert it into business value. Your raw documents (PDFs, scans, images) are transformed into structured formats compatible with any system:
Databases: Direct export to SQL (PostgreSQL, MySQL) or NoSQL (MongoDB).
Spreadsheets: Cleanly formatted Excel (.xlsx) or Google Sheets with preserved table structures.
Business Systems: Direct API integration with your CRM, ERP, or custom dashboard.
Service Highlights
- Automated end-to-end OCR and Document Processing workflows
- Deployment options: Fully offline (Local) or Hybrid Cloud
- Advanced Table Extraction using Docling and computer vision
- Orchestration via n8n for seamless integration
- High-volume batch processing for large archival migration
- Intelligent pre-processing: classification, validation, and key-field detection
- Seamless export to CRMs, ERPs, spreadsheets, or custom SQL databases
- Zero manual effort - eliminate data entry and human error